I thought it would be good to put up the physical and logical models of Velocity so you can all get a grasp of what it looks like.
Physical Topology
Below is the physical topology of a Velocity caching tier. As you can see, each cache cluster contains one or more cache servers (hosts) with an instance of Velocity running on it as a Windows service. The individual hosts are each cognizant of a folder share the contains information that links them all together in a cluster (Microsoft understands this is a single point of failure, and intends to solve this by RTM). This is one level at which the synchronization of caches occurs.
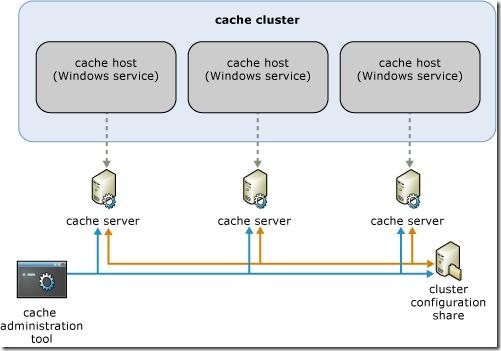
Obviously, you can just keep adding more servers to the cluster in order to scale. Each server in the cluster is configured with a service port (for cache communication), a cluster port (for administration), and a memory governor that controls how much memory is allocated on the server for the cluster. This configuration happens at install, as seen below:
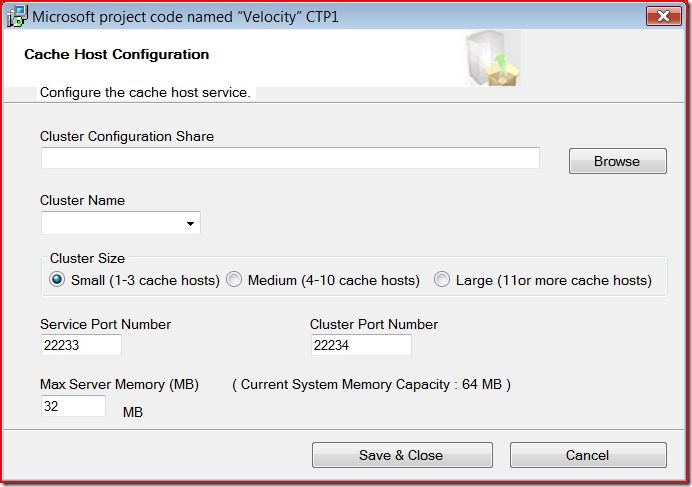
The Cache Administration Tool noted in the diagram above is a command line tool that provides simple control and diagnostic functions, allowing administrators to start and stop clusters, hosts, and get real time statistics about cache inventory.
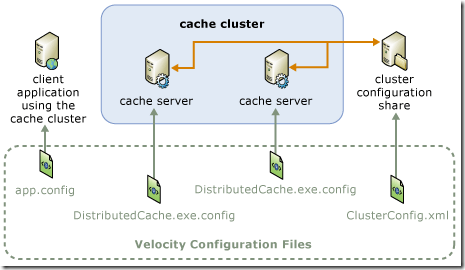
Each application has a reference to one or more host, through the web.config or app.config. Velocity will then determine the host to retrieve the cache from. Below is a diagram of the configuration topology:
Logical Topology
Below is the logical model of Velocity. You can see that there are three different ways in which you can store caches across clusters. You can use the default cache, a named cache, or a region.
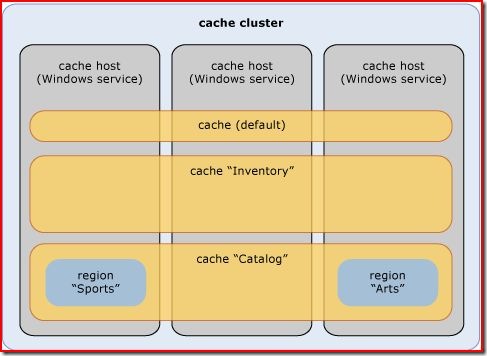
If you're using a single cluster for a single application, using the default cache will suffice. However, if you're using the same cache cluster for multiple applications, then a named cache should be used in order to logically partition your applications (think one named cache per database). At the named or default cache level, you can configure cache policies individually such as fail-over, expiration, and eviction.
Regions are caches that can be created as a subset of a named cache. Region caches are guaranteed to exist on a single host server. Though not entirely clear to me, I've gathered that the Velocity internals use this as a unit for replication within named caches (behind the scenes), and they've made it available in the case that you'd like to skip the overhead of routing, and go directly to a cache location for your data.
That's it for the topology. Hope it gave you a good understanding of how Velocity is organized and how it's solving the problem of distributed caching.


1 comments:
I think Velocity CTP1 leaves much to be desires and CTP2 is only a marginal improvement over CTP1. I feel it will be some time before Microsoft stabalizes Velocity to a level where it is acceptable for serious environments.
In the meantime, NCache already provides all of CTP1, CTP2, and many more features. NCache is the first, the most mature, and the most feature-rich distributed cache in the .NET space. NCache is an in-memory distributed cache for .NET and also provides a distributed ASP.NET Session State. Check it out at http://www.alachisoft.com.
NCache Express is a totally free version of NCache and good for 2-server clusters. Check it out at http://www.alachisoft.com/rp.php?dest=/ncache/ncache_express.html.
Post a Comment