Generally my interviews go like this. They may fluctuate depending on the skill of the candidates, but in almost all cases, this line of questions is sufficient to determine the skill of the candidate, without any ambiguity.
I introduce myself to the candidate and I let them know what I do, what I’m responsible for and also my level of technical detail. I’ll also at this point let them know that the interview is going to be technical one.
Then I’ll setup the next line of questioning. I try to get a feel for how well they remember their data structures. I then let them know I’ll be talking to them about the Binary Search Tree. Then, I let them know that I’m not necessarily worried about whether or not they remember all the details, but am focusing on their problem solving skills.
Sometimes the candidate tries to make this problem more complicated than it is by thinking about balancing the binary search tree. So I usually let them know at this point if they have some recollection of binary search trees that they shouldn’t worry about balancing the tree and that unbalanced trees are perfectly fine for this example. If the candidate does seem to remember these concepts fairly well, then maybe I’ll ask later on how they would go about balancing a BST.
The first question I ask is if they remember the properties of the binary search tree. If they don’t then I ask them if they could describe a general tree structure. Anyone with any sort of programming background should be able to describe a tree. If they recall the tree structure, but don’t recall the BST, I let them know the properties of a BST. What I am getting to here is that I want it to be clear that a BST is tree structure in which the value of the left node is less than the parent node’s value, and the value of the right node is greater than the parent node’s value.
Here’s where we get into the question. Usually I give them this simple array (now, you might be thinking this is really simple, but you’d be so surprised at how few people actually get this stuff.)
[4, 2, 6, 1, 7, 3, 5]
Then I’ll ask them to walk me through how they would take that array of values and arrange them in a BST structure, if they were serially iterating over that array, and not using any temporary storage devices (they almost always want to go to 1 first, and I almost always tell them that they can’t do that, because they’ll be losing their place in the array.)
I’m expecting something like the following:
 Step 1
Step 1
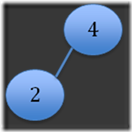 Step 2
Step 2
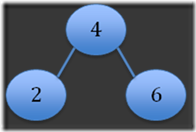 Step 3
Step 3
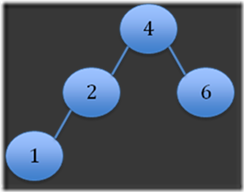 Step 4
Step 4
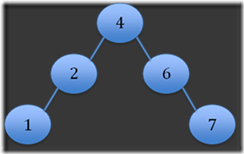 Step 5
Step 5
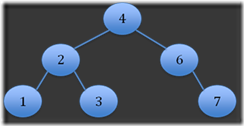 Step 6
Step 6
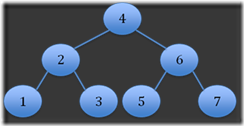 Step 7
Step 7
Simple right? You should see some of the answers I get.
Once they’ve successfully done that, I ask them what the advantages of this structure are over an array. I’m expecting to hear that it is more performant than an array because the search time is less as it divides the results based upon the path of the tree. If they’re totally up to speed on this, I’ll ask them the order of magnitude of this performance gain. I’m expecting to hear log(n).
Once we’ve chatted about this, I’ll ask the candidate to model a BST in the language they are most comfortable in. In C#, I'm looking for an answer like so:
public class BST
{
public int Value;
public BST LeftNode;
public BST RightNode;
public BST(int value, BST leftNode, BST rightNode)
{
Value = value;
LeftNode = leftNode;
RightNode = rightNode;
}
}
Sometimes they don't get to exactly this (again, you'd be surprised at some of the answers that you get here.) So what I'll do is discuss why they did it the way they did, and then we eventually end up here.
Next I'll ask them to construct a simple tree that looks like step 3 above using the constructor that they've defined above. What I'm expecting is something like this:
BST myBst = new BST(4, new BST(2, null, null), new BST(6, null, null));
Usually they'll have three or four lines of code for the constructor. If they do, I'll immediately ask them to get it down to a single line of code.
After this I'll do some small, short questions off of their resume, and dig in a bit about what they're doing.
After that I'll ask them "What questions do you have for me?" It's important to phrase it this way because it insinuates an expectation that they have questions for me.
All of this usually fits into a 45 minute time slot, which is usually what I've been given as an interviewer historically.
Again, this simple flow really gives me a great idea of the candidate's technical skill. It works really well for entry level to mid-level candidates, it can be language agnostic, and it's really unambiguous.
Why am I writing about this? Well, I'm going to switch it up. I'm going to stick to this type of questioning, but I think I'm going to try a new computer science concept. Could be another structure, could be a sorting algorithm, could be a balancing problem, who knows.