Scalability always seems to be the poster child for YAGNI. Lately however, the barrier to entry of scaling out is decreasing as the services that provide elastic infrastructures are wildly abundant. Scaling a website is easier now than ever for just about anyone, but for some reason upfront scalability design seems to still be a bit taboo.
I wanted to test how difficult it would be to do upfront scalable implementation, and pay little or nothing until the scaling needed to happen. So, I decided to dive in and see how I would create a site that needed to start with serving a small number of pages, do a little bit of work, and use a little bit of storage, while paying a little bill, but with the ability to scale out the web page serving, the work, and the storage, infinitely.
Recently my Dad was asking how to download all the photos from a set in Flickr so he could burn them to a CD for my grandmother. There's a few desktop apps and Firefox extensions for it, but everything requires you to have to download and install software or use a certain browser. So, I thought a web application that looks at a picture site, and zips up the original images in a set or album and let's the user download them would be a good sample application for this test. You can see the application here.
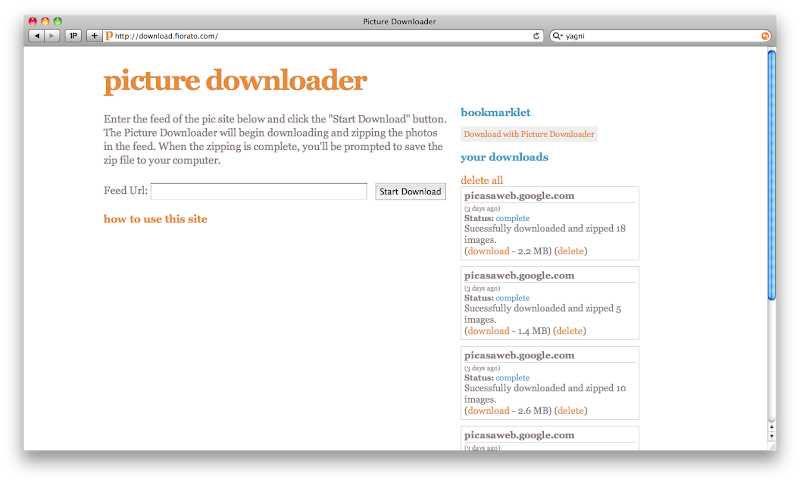
Overview
The application itself can be divided into three parts. The web application, which serves as the interface for both the user and the workers; the workers, which download the images and zip them up; and storage which stores the zipped sets for download.
Web App
The web app is a pretty vanilla Ruby on Rails web application. It serves up a single page for the user to enter the information about the set/album they want to download, and it also provides a REST interface for the workers to talk to. This is where the PostgreSQL database resides, and stores the information about the downloads that have been requested.
To get cheap scalability, it's deployed to a host called Heroku. Heroku is an infrastructure that provides process-level scaling for web based Ruby applications. When you deploy an application to Heroku, it complies it into a "slug" and this "slug" can be started as a process on a server. Heroku uses Amazon's EC2 infrastructure and deploys the "slug" to a user-specified number of load balanced processes, with processing slots available across the virtual servers they have running at Amazon. You pay for the number of processes you want to have. 1 process is free, so you can host a low traffic website there for no money at all and scale up the pay scale as you need it.
Workers
The workers are Ruby scripts that do the actual downloading and zipping of the set/album. Workers are doing periodic lightweight polling of the web app, looking for new jobs to work on. Once a job is completed the zip is moved to the shared storage, and the worker tells the web app that the job is done and gives the location of the zip file.
To get cheap scalability, the workers run on Amazon's EC2 environment. There are two workers per server, and when the Amazon EC2 instance starts up, the code is updated from Git, and the processes are started as service daemons. The EC2 instances are started by the web application, and they shut down after an hour of inactivity. The web application determines how many EC2s to start based upon the number of jobs in the queue. At $.03 per hour, I pay nothing for no activity, and very little as the application scales up.
Storage
Since the web app and the workers are physically separated, I needed shared storage that would accommodate for potentially some really large zip files. Additionally, I needed a network that could serve such files reliably for download.
To get cheap scalability, I used Amazon's S3 storage for this shared storage. I get great copy speed from the EC2s to the S3 storage, since they're both on Amazon's network, and again, I only pay for what I use. At a minimum, I have to pay for the storage of the EC2 image, and on top of that, I pay for the zip files that are stored there, as well as for the data transfer and requests. You can see the pricing here, and you'll see that it's very affordable. The zip files are deleted after a month, to control storage costs.
Conclusion
Overall this project took me very little time to do, around 30 hours. With it, I've got a solution that costs me nearly nothing if it isn't used, and would be affordable if it was used quite a bit. That said, it's a pretty simple application, and the lines of separation between web app/workers and storage were very clear, so you're mileage may vary.
Also, you probably were wondering about database scaling. In this situation the PostgreSQL scaling would happen vertically, adding more dedicated resources to the database server, rather than more databases to the pool, whichHeroku supports as well.
I do need to give credit to my colleagues at the Nextpoint Lab who initially put together the scalable design for our software (which gets raving reviews, I'm just sayin'), as it was essentially the blueprint for this design.
I think my conclusion is that if the situation is right, upfront design and implementation of a scalable solution doesn't necessarily have to cost you an arm and a leg to get it done, nor does it need to be a huge gamble if the scale isn't needed immediately.


3 comments:
Great Article it its really informative and innovative keep us posted with new updates. its was really valuable. thanks a lot.
seo company
I have not heard about before. Keep sharing more blog posts on this Community and get extra benefits with this ideas and knowledge. Thanks for this one.
curious technocompe
dailystrength
technocompe dailystrength
thanks for sharing best topics, keep such update and share best ideas over to all and me so i very happy with this.
Article Dunia
Trading Article
Post a Comment